Convert 4D-Array Image (with RGBA Channels) to Normal 3D-Array Image
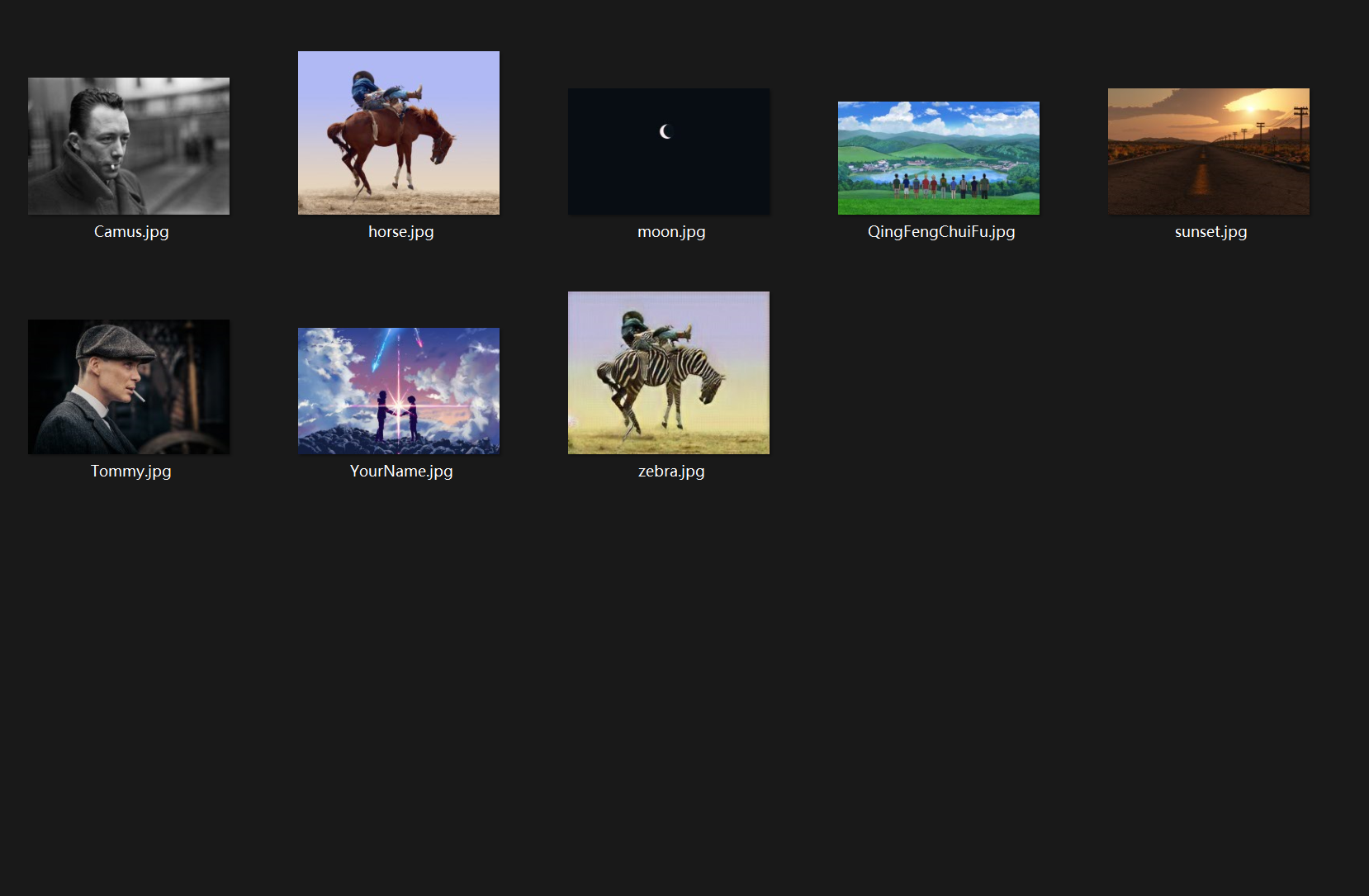
In blog1 I take following images to test the image-captioning model ImageCaptioning.pytorch2:
However, when I added the image below, R66.png, to be captioned:

I got an error saying:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Traceback (most recent call last):
File "G:\...\ImageCaptioning.pytorch-master\eval.py", line 136, in <module>
loss, split_predictions, lang_stats = eval_utils.eval_split(
^^^^^^^^^^^^^^^^^^^^^^
File "G:\...\ImageCaptioning.pytorch-master\eval_utils.py", line 84, in eval_split
data = loader.get_batch(split)
^^^^^^^^^^^^^^^^^^^^^^^
File "G:\...\ImageCaptioning.pytorch-master\dataloaderraw.py", line 115, in get_batch
img = Variable(preprocess(img))
^^^^^^^^^^^^^^^
File "G:\...\venv\Lib\site-packages\torchvision\transforms\transforms.py", line 95, in __call__
img = t(img)
^^^^^^
File "G:\...\venv\Lib\site-packages\torch\nn\modules\module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "G:\...\venv\Lib\site-packages\torch\nn\modules\module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "G:\...\venv\Lib\site-packages\torchvision\transforms\transforms.py", line 277, in forward
return F.normalize(tensor, self.mean, self.std, self.inplace)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "G:\...\venv\Lib\site-packages\torchvision\transforms\functional.py", line 350, in normalize
return F_t.normalize(tensor, mean=mean, std=std, inplace=inplace)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "G:\...\venv\Lib\site-packages\torchvision\transforms\_functional_tensor.py", line 926, in normalize
return tensor.sub_(mean).div_(std)
^^^^^^^^^^^^^^^^^
RuntimeError: The size of tensor a (4) must match the size of tensor b (3) at non-singleton dimension 0
which prompts that, the image is a 4D array, that is besides RGB channels this image file has an additional alpha (A) channel (used to specify opacity)3. So, it cannot be normally processed by certain PyTorch function. We can verify this point by printing array size of each input image:
1
2
3
4
5
6
7
8
9
10
11
from PIL import Image
import numpy as np
import os
folder_path = '.'
for file_name in os.listdir(folder_path):
image_path = os.path.join(folder_path, file_name)
if file_name.endswith(('.png', '.jpg')):
image = Image.open(image_path)
print("%-19s: %s" % (file_name, np.array(image).shape))
1
2
3
4
5
6
7
8
9
Camus.jpg : (900, 1321)
horse.jpg : (1220, 1500, 3)
moon.jpg : (1800, 2880, 3)
QingFengChuiFu.jpg : (1080, 1920, 3)
R66.png : (1800, 2880, 4)
sunset.jpg : (1200, 1920, 3)
Tommy.jpg : (3412, 5118, 3)
YourName.jpg : (1200, 1920, 3)
zebra.jpg : (256, 316, 3)
To avoid above error, we could use convert function4 to convert RGBA image to RGB image:
1
2
3
image = Image.open("R66.png").convert('RGB')
print(np.array(image).shape)
image.save("R66_RGB.png")
1
(1800, 2880, 3)
After conversion, the image-captioning model can caption it as usual:
1
".\data\images\new_images\R66_RGB.png": a close up of a yellow and orange cat
But, in this caption the only right part is “yellow” 😂 Having said that, anyway, this image becomes a valid input for the model.
By the way, due to that R66.png is the only image with .png extension among those figures, so I guess that PNG file may be always an image with RGBA channels, but above result illustrates that I was wrong.
References