Smaller learning rate could prevent from loss value becoming NaN in a way when training GAN
Recently, I’ve been training a GAN (Generative Adversarial Net) in MATLAB for my personal research. GAN is a famous network structure, but it’s also very difficult to train in some specific scenarios. During my training process, I found GAN has a possibility to encounter the case that loss values become NaN while training, and without any early signs, like:
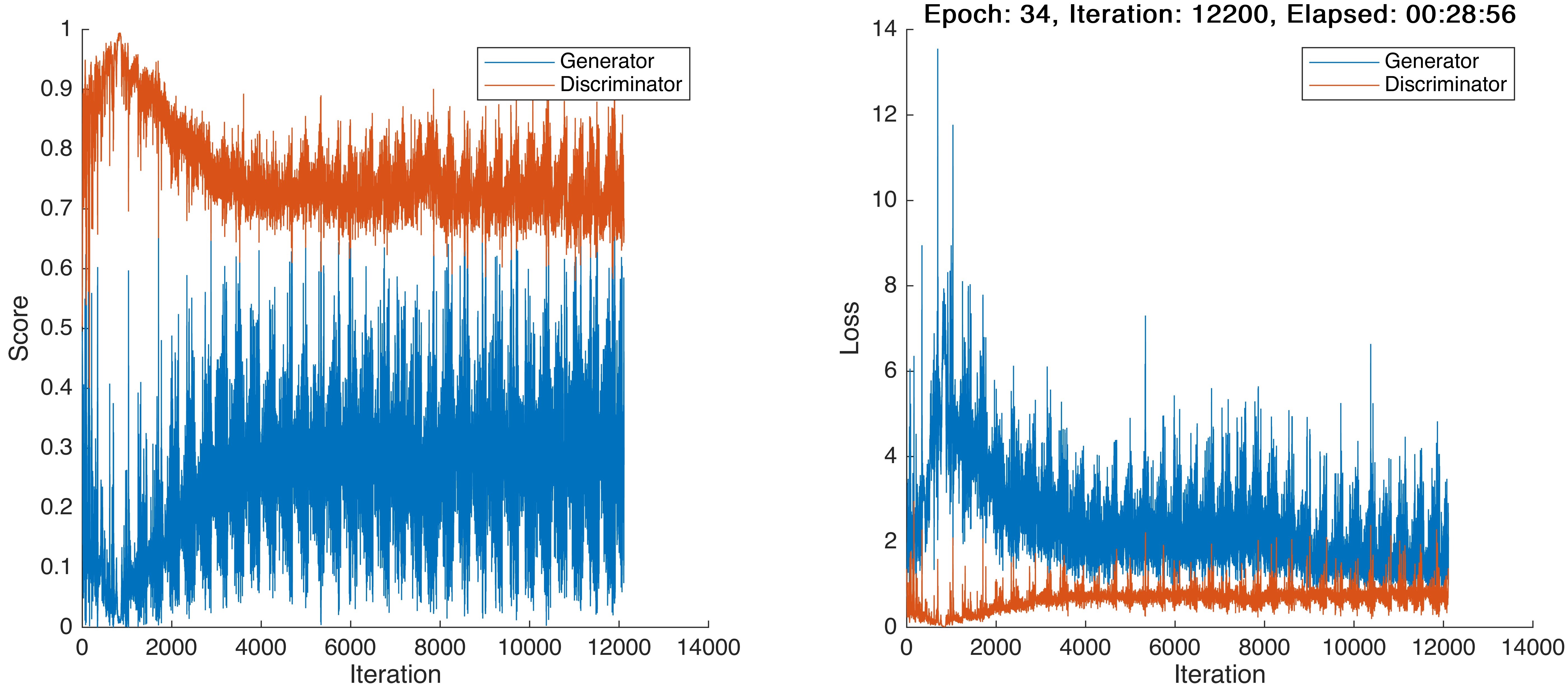
For confidential sake, here I just show the change progresses of scores and loss, but actually, the samples generated by Generator become all NaN values correspondingly.
It can be seen that, either of loss values of Generator and Discriminator doesn’t have a tendency to converge to a extremely small value, nor diverge to Inf. NaN seemingly appears suddenly.
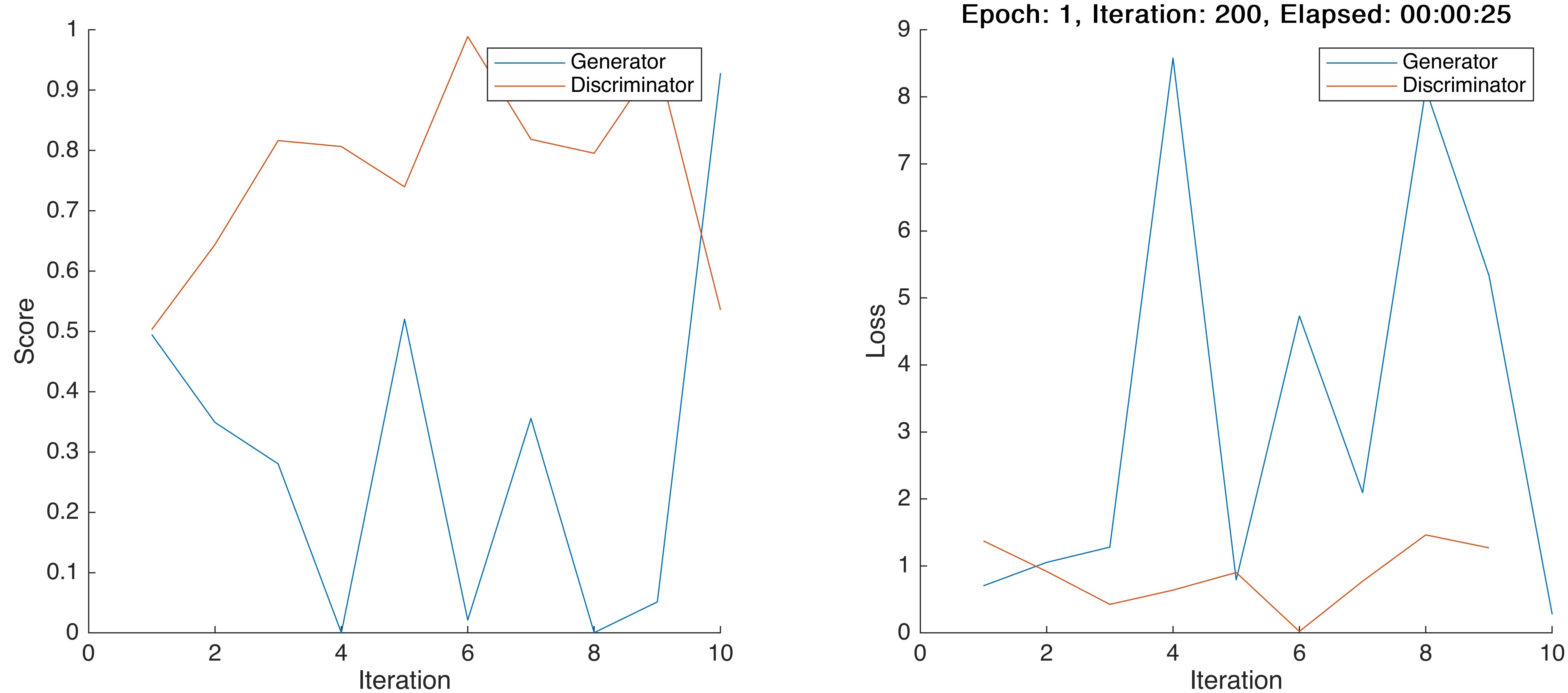
Later on, I found learning rate would have an impact on this phenomenon. In the above case, the learning rate is set as 0.0001, and if I increase it to 0.001 (ten times larger), the loss will become NaN just after 10 iterations:
If I decrease learning rate to 0.00001 (ten times smaller than that in the first case), Generator and Discriminator will approach the equilibrium more after a relatively long training process:
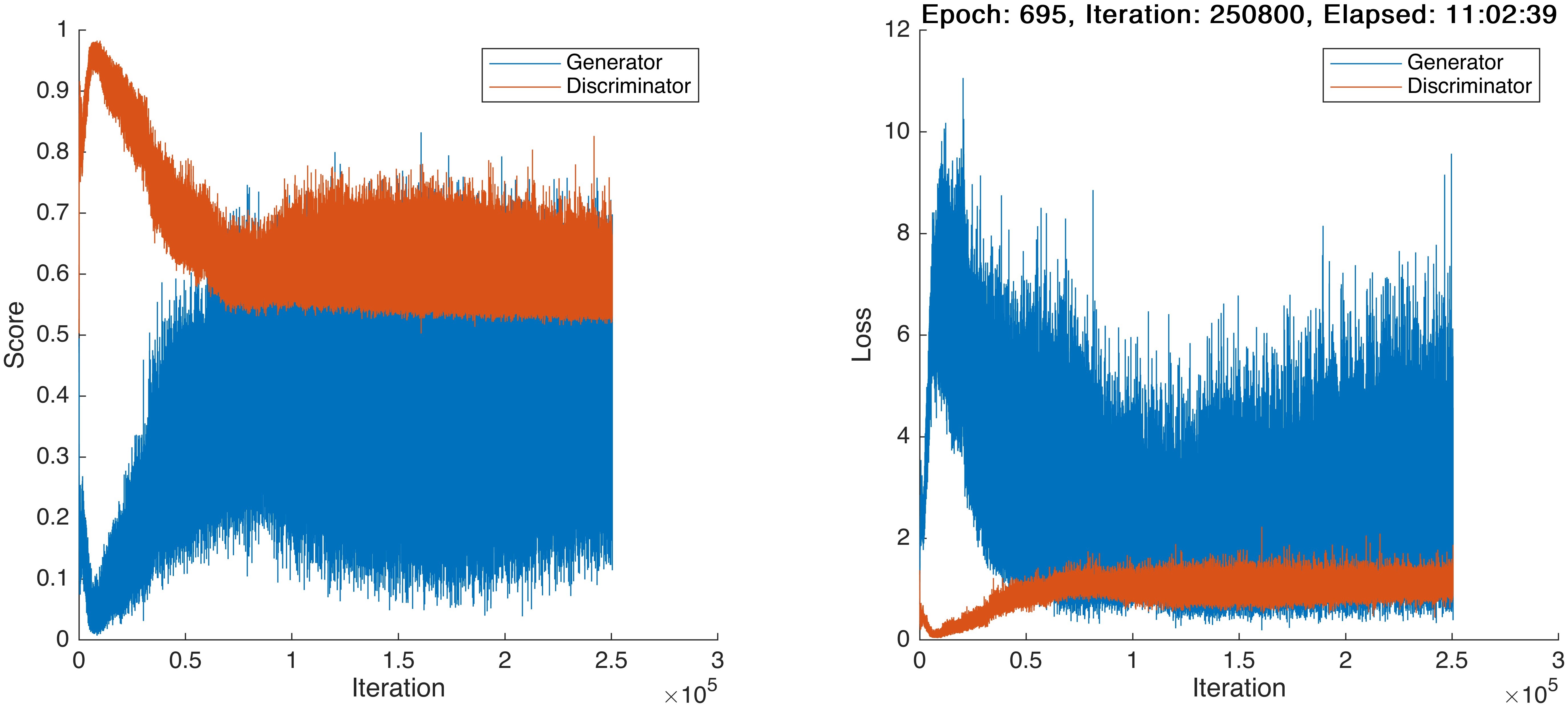
BUT, loss eventually becomes NaN in this case, too. So, a smaller learning rate can help to improve the training process to some extent, but for my case, it can’t completely prevent from loss value becoming NaN. And as can be seen from the above figure, further reducing the learning rate may be helpless, because loss values, especially that of Generator, converge so slowly. There must be other inappropriate settings for this GAN.